En tant que développeur, j’adore quand une idée un peu abstraite se transforme en un projet concret. Récemment, je me suis lancé un défi : créer une application capable de résumer intelligemment un texte. Cela m’a plongé dans le monde fascinant du NLP (Traitement du Langage Naturel) et, plus spécifiquement, dans l’entraînement d’un modèle d’IA.
Loin des grands discours, je vous propose un retour d’expérience transparent sur ce parcours : des premiers choix techniques aux obstacles imprévus, jusqu’au moment où la magie opère (ou pas tout à fait).
L’idée de départ : Du résumé de texte au défi du « NER »
Mon objectif initial était simple : faire du résumé de texte. Mais pour bien résumer, une IA doit d’abord comprendre de quoi parle le texte. Qui ? Quoi ? Où ? C’est ce qu’on appelle la Reconnaissance d’Entités Nommées (ou NER en anglais). Il s’agit d’identifier dans une phrase les noms de personnes, d’organisations, de lieux, etc.
Pour y arriver, j’ai exploré plusieurs outils :
- TensorFlow : La célèbre bibliothèque de Machine Learning de Google.
- TensorFlow.js : Sa version JavaScript, qui a le potentiel énorme de faire tourner des modèles directement dans le navigateur du client, sans serveur.
- Hugging Face : Une plateforme incontournable qui donne accès à des milliers de modèles d’IA pré-entraînés.
Le premier obstacle : Le français, cette belle langue si complexe pour l’IA
Mon premier réflexe a été de chercher un modèle NER pré-entraîné en français et compatible avec TensorFlow.js. Et là, premier mur. Si les modèles pour l’anglais sont légion, trouver la perle rare pour le français s’est avéré compliqué.
J’ai alors identifié un champion de la compréhension du français : CamemBERT. C’est un modèle de langage extrêmement puissant, mais c’est un généraliste. Il comprend la langue, mais il n’est pas spécialisé dans la tâche précise de NER.
La solution ? Ne pas chercher un autre modèle, mais spécialiser celui-ci. C’est ce qu’on appelle le fine-tuning.
La solution : Apprendre à CamemBERT un nouveau métier
Le fine-tuning, c’est un peu comme prendre un expert en linguistique (CamemBERT) et lui apprendre un métier très spécifique (identifier des personnes, des lieux…). Pour cela, il faut l’entraîner avec des exemples concrets.
J’ai utilisé le jeu de données WikiAnn, qui contient des milliers de phrases issues de Wikipédia où les entités sont déjà étiquetées (ex: « Paris » -> LOC, « Victor Hugo » -> PER).
L’entraînement s’est déroulé en trois temps, un cycle répété des milliers de fois :
- Observer : On montre au modèle une phrase et les bonnes réponses.
- Deviner : On lui donne une nouvelle phrase, et il tente de trouver les entités tout seul.
- Se corriger : On compare sa prédiction à la bonne réponse. S’il se trompe, il ajuste ses paramètres internes pour s’améliorer la prochaine fois.
Le compromis crucial : 10 minutes ou 6 heures d’entraînement ?
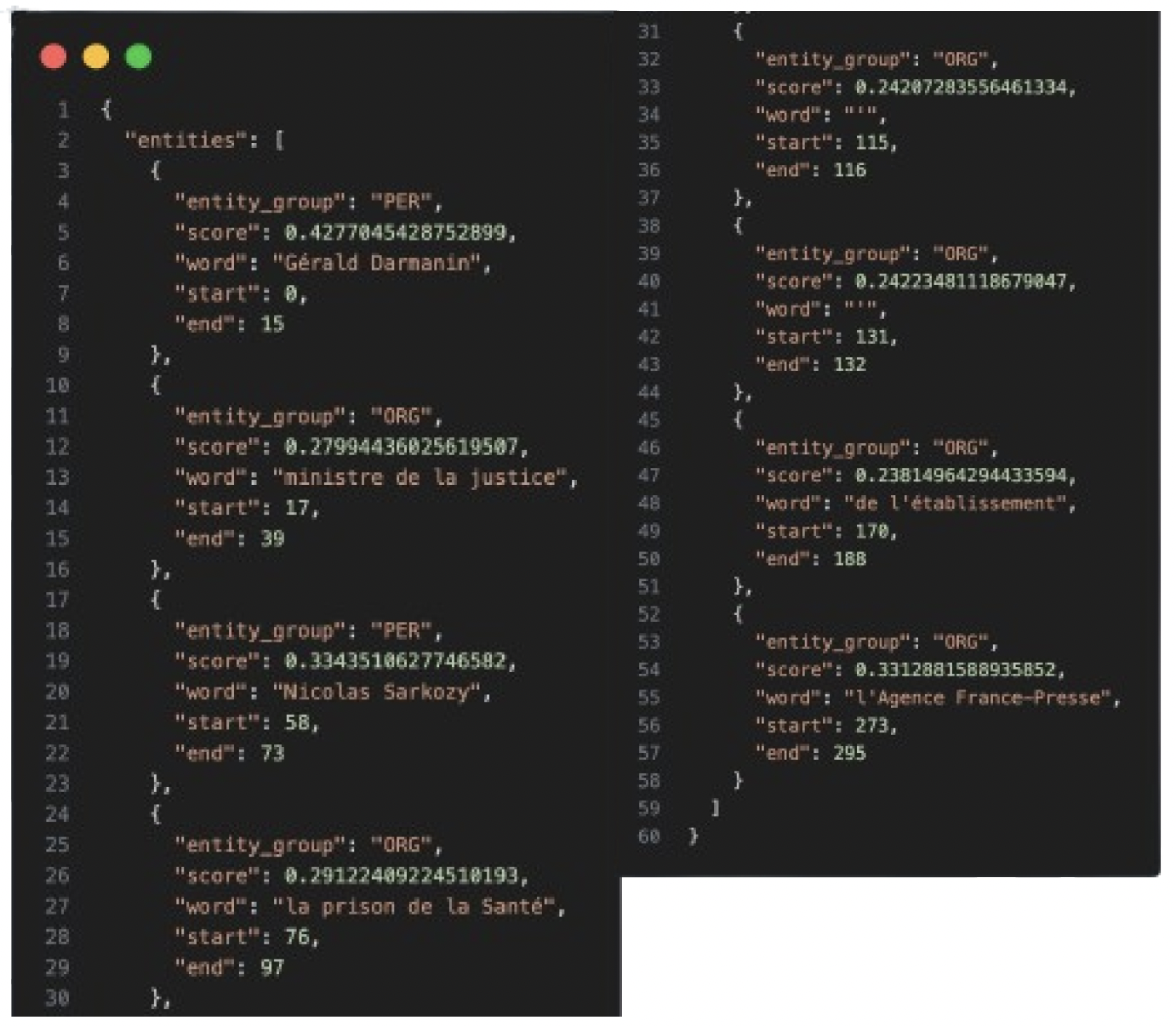
C’est ici que l’expérience devient fascinante. L’entraînement d’un modèle peut être très long. Pour mes premiers tests, j’ai utilisé une version réduite du jeu de données. Durée : 10 minutes.
Pour la phrase : « Gérald Darmanin, ministre de la justice, a rendu visite à Nicolas Sarkozy… », le modèle a bien identifié « Gérald Darmanin » comme une personne (PER), mais avec un score de confiance de seulement 42%. C’est bien, mais pas très rassurant.
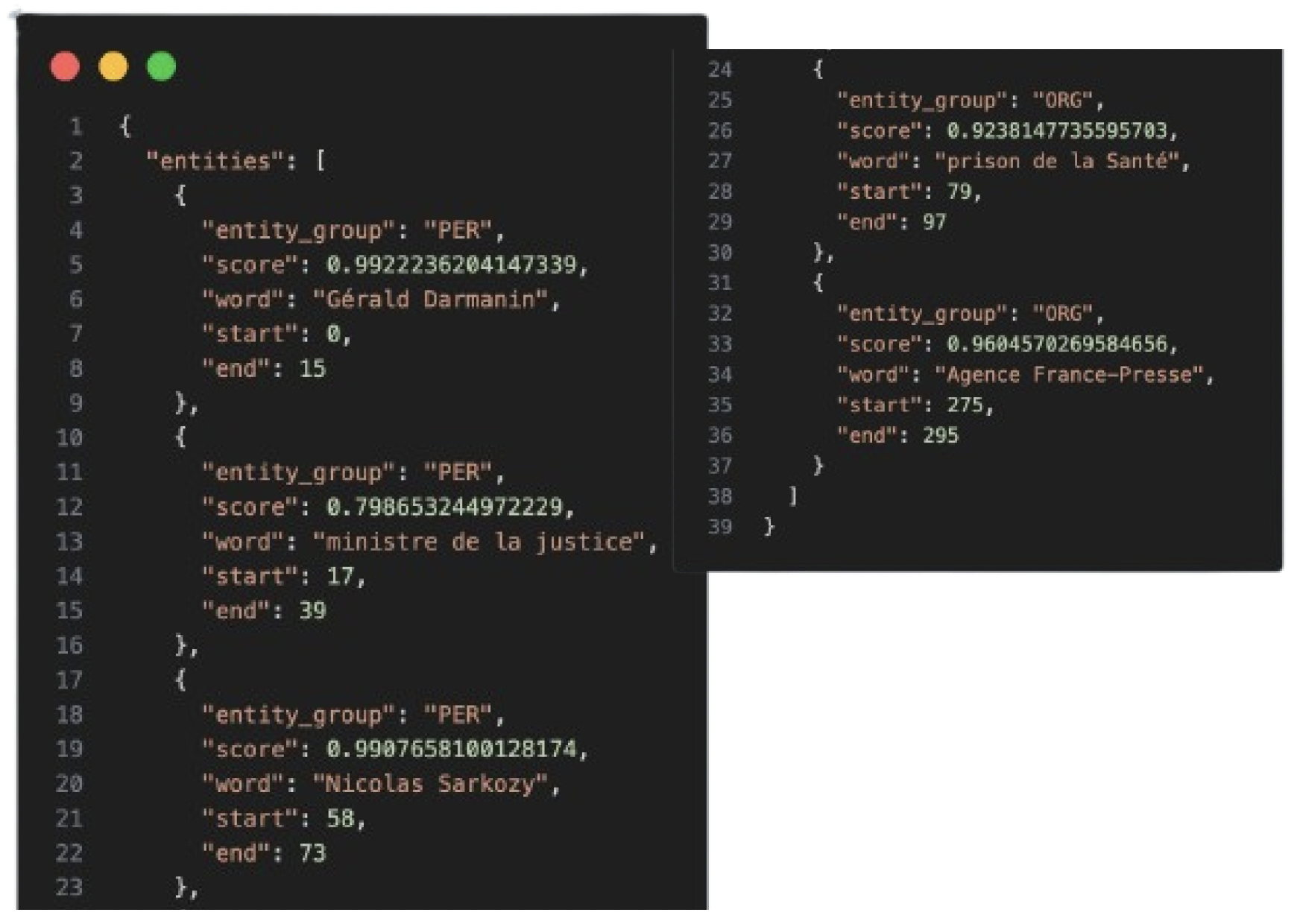
J’ai ensuite lancé l’entraînement complet. Durée : 6 heures.
Avec ce nouveau modèle, le score de confiance pour « Gérald Darmanin » est passé à 99% !
La différence est énorme. Ce retour d’expérience montre de manière très concrète un principe clé en IA : le temps et la qualité des données investis dans l’entraînement ont un impact direct et massif sur la performance du modèle.
Résultat d’un modèle avec 10min d’entrainement
Résultat d’un modèle avec 6h d’entrainement
Et maintenant ? Déploiement et prochaines étapes
Pour rendre ce modèle utilisable, j’ai fait le choix pragmatique de créer un backend en Python pour l’exposer via une API, plutôt que de me battre pour le convertir en TensorFlow.js dans un premier temps. Une application React consomme maintenant cette API pour analyser du texte en temps réel.
Ce projet n’est pas fini. Les prochaines étapes sont claires :
- Améliorer la détection : Entraîner le modèle à mieux reconnaître les dates et les montants.
- Explorer TensorFlow.js : Revenir à l’idée de départ et tenter de convertir ce modèle affiné pour l’exécuter entièrement dans le navigateur, pour une meilleure réactivité et un usage hors-ligne.
Ce qu’il faut retenir
Ce projet m’a appris que l’entraînement d’une IA est un parcours fait de pragmatisme. Il faut savoir adapter ses ambitions aux outils disponibles, comprendre que la qualité se paie (en temps de calcul !) et ne jamais sous-estimer la puissance du fine-tuning pour spécialiser un modèle généraliste.
C’est cette approche itérative et orientée solution que nous aimons mettre en pratique chez Atecna.
Vous avez un projet IA en tête ? Discutons-en !
Envie d’échanger avec la Team IA ?
Ils seront ravis de répondre à vos questions !